¶ Python Deployment - KubeFlow
This is a farely technical view of the practices used to create pipelines when using the library kfp.
¶ Imports
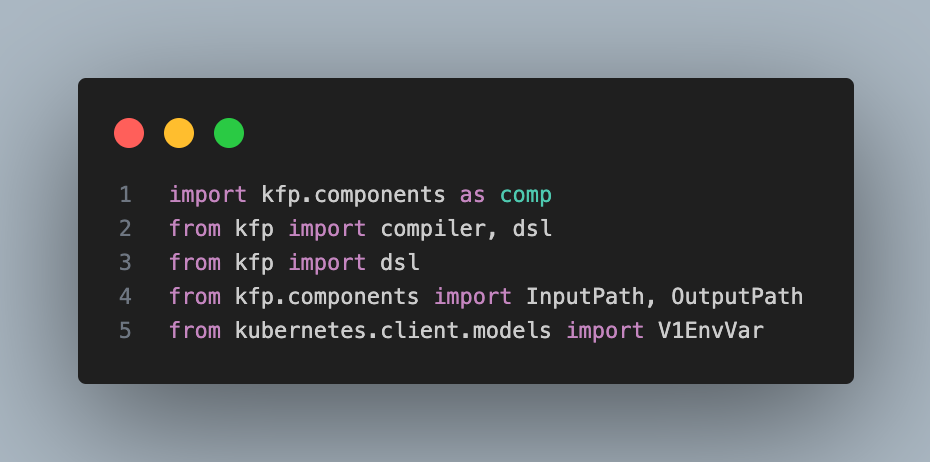
These are the libraries necessary to create a pipeline (without considering the ones used in the pipelines themselves).
¶ Function definition
The way to create pipelines is to build functions that then are turned into components. These components are then turned into task which are just executions of said components. The components can be also saved into .yaml files to be reused several times.
Here is an example of a function which will be interpreteted as a pipeline
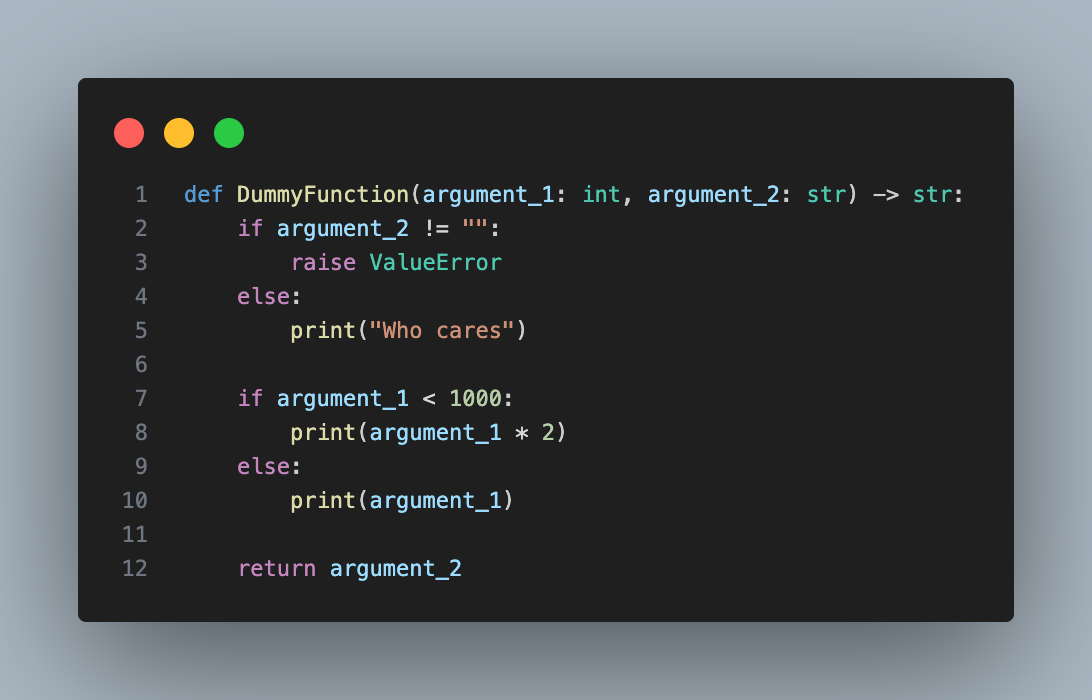
It is not necessary to specify the types of the input for the function but it is recommended as a standard practice.
¶ Pipeline definition
In order to create a pipeline, different tasks as component executions have to be implemented.
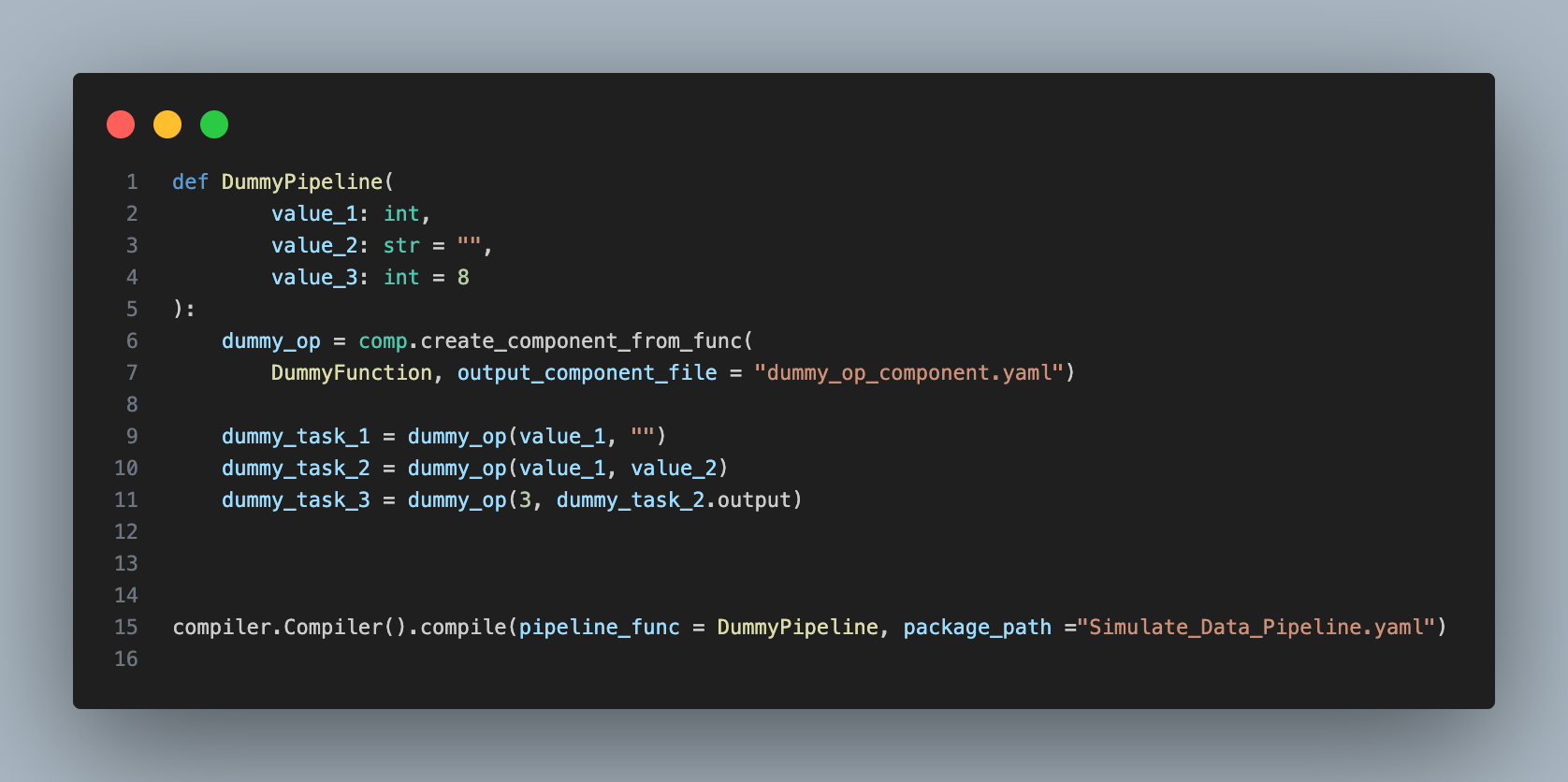
This pipeline has three input arguments. Only one (value_1) is required to run as the others have default arguments. The pipeline executes the dummy function three times with different values. A task can use the output of another task which will link them as one going after the other.
The execution of last piece of code (compiler.Compiler...) creates a .yaml file in the package_path. That .yaml file is the one used when uploading the pipeline in KubeFlow (Kubeflow Pipelining).
There is additonal information in the Readme files for Pipelines.