¶ 5. Forecasting Service
This guide will help you to configure the forecasting service in the installed RENergetic system.
¶ What is the Forecasting Service?
Forecasting is one of the main functionalities developed for RENergetic. Its goal is to be able to predict the future behavior of any of the measurements found in the system’s database. The tasks done by this subsystem are:
- Train and host time series artificial intelligence (AI) models for forecasting
- Forecast the future values using the models trained before
- Supervise and maintain the models
This page serves as a guide on how to set up the forecasting service for an asset. Further explanation of how the system works can be found in:
Forecasting Components - Description of the KubeFlow Pipelines used in Forecasting
FAST Dynamic Class - Description of Custom Forecasting in KubeFlow
Anomaly_Detection - Description of Anomaly Detection
¶ Example of use
Each combination of measurement-asset may have its own time series to train a model. To show this, let's examine an imaginary asset "building1" which has one measurement called "energy-meter". For this we expect the values of the time series stored in the InfluxDB as:
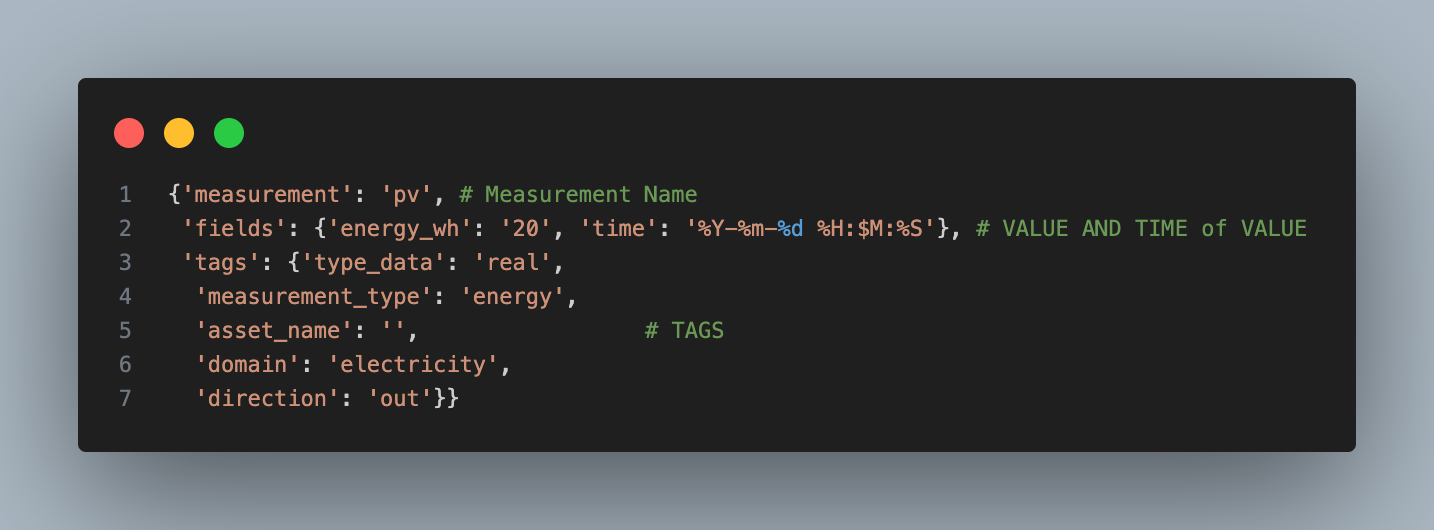
¶ 1. Training
From this, a model can be trained for that measurement-asset time series by executing a run of the pipeline "training-model" with the following arguments:
- url_pilot: URL of the Influx DB for the pilot
- diff_time: Difference of time between measurements in minutes (Example 17:00 - 17:15 --> 15 minutes)
- filter_dict: Dictionary of the filters to apply to the data. Example: {“val1”:[val1_1,val_1_2]} means that the data will be filter for the values val1_1,val_1_2 of the column val1.
- Path_minio: URL of the minio server
- Access_key: Access key to access the minio server
- Secret Key: Secret key to access the minio server
- Min_date: Begin date for training data
- Max_date: End date for training data
- Dict_assets: Dictionary of the measurements to use for training. As an example:
- Key_measurement: Key for the value of the measurement . See details below
- Type_measurement: If the Tag Type needs any filtering . See details below
- Pilot_name: Name of the energy island
- Hourly_aggregate: If there is a need for aggregation in hourly values: mean, max, min
- Minute_aggregate: If there is a need for aggregation in minutely values: mean, max, min
- Forecast_models: Names of the models that will be trained
- Set_models: Binary, if the best model will be set as main model or not
- Num_days: Number of days to use as test
¶ 2. Forecasting
Once the model is trained, a forecasting run can be set in the pipeline "forecasting-pipeline", which would use the following arguments:
- url_pilot: URL of the Influx DB for the pilot
- diff_time: Difference of time between measurements in minutes
- filter_dict: Dictionary of the filters to apply to the data. Example: {“val1”:[val1_1,val_1_2]} means that the data will be filter for the values val1_1,val_1_2 of the column val1.
- Path_minio: URL of the minio server
- Access_key: Same as previous pipeline
- Secret Key: Same as previous pipeline
- Num_days_predict: Number of days to forecast ahead
- Num_days_check: Days to check data
- Dict_assets: Dictionary of the measurements to use for training. As an example: {“Measurement_1”: [“asset_1”, “asset_2”]
- Key_measurement: Key for the value of the measurement
- Type_measurement: If the Tag Type needs any filtering
- Pilot_name: Name of the pilot
- Hourly_aggregate: If there is a need for aggregation in hourly values: mean, max, min
- Minute_aggregate: If there is a need for aggregation in minutely values: mean, max, min
- Availability_minimum: Minimum percentage for the availability check
- Send Forecast: Binary, if the forecast is sent or not to the InfluxDB
- Send Notification: Binary, if the anomaly notification is sent or not or the Postgres API for notifications