¶ 13. Kubeflow Pipelining
KubeFlow is the ecosystem used in RENergetic for the managing of the entire AI cycle, i.e., training the forecasting models, making the predictions and monitoring and toggling retraining.
Within the RENergetic system there are three main pipelines already in production (See Forecasting) for documentation. The site for KubeFlow is very extensive in its details (source: KF Webpage). To ease the introduction to Kubeflow we provide this page with all the necessary information to understand KF and its utilisation in the RENergetic system.
This is the main page of the KubeFlow Dashboard.
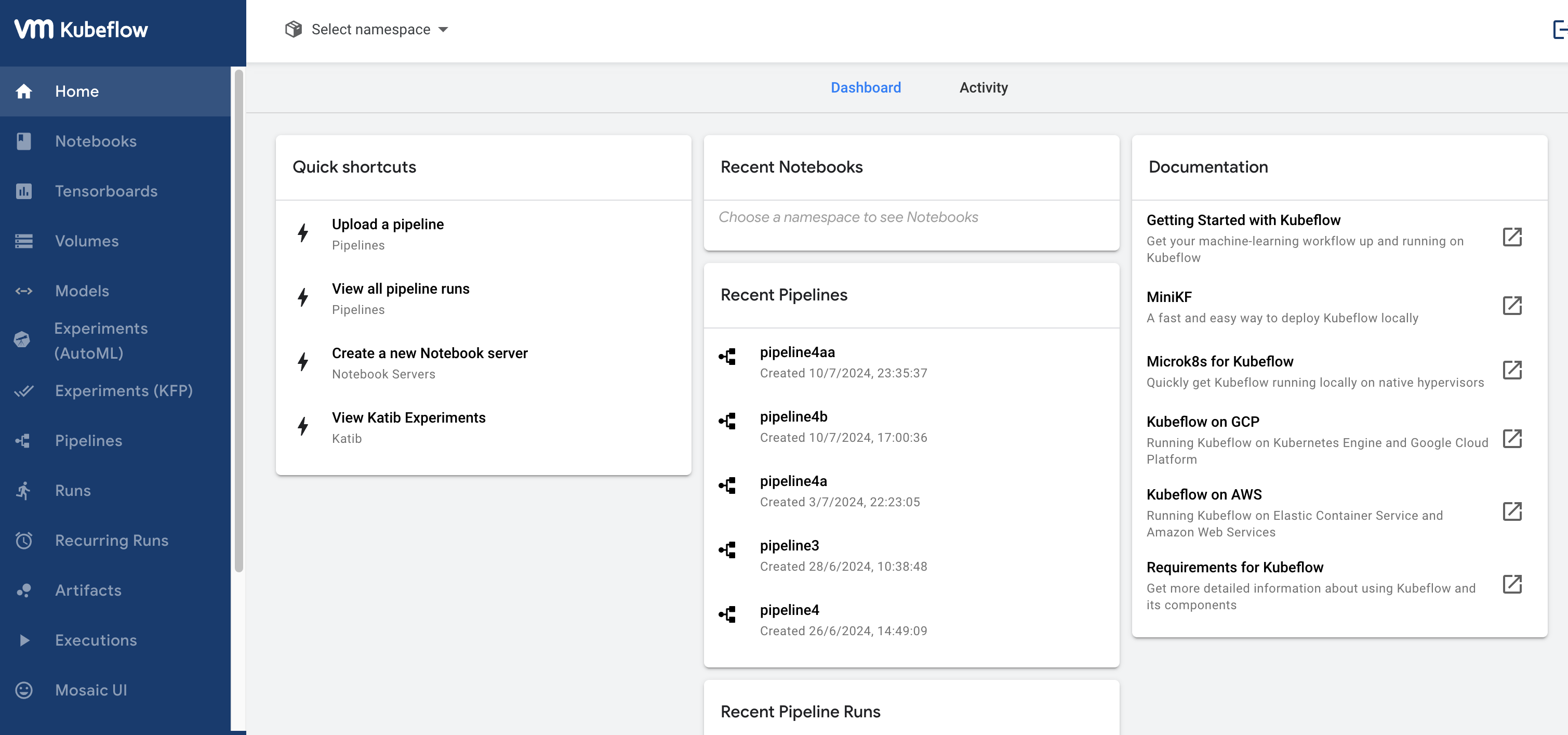
From here we can access the many functionalities of the models.
The main 4 subpages of KubeFlow used in RENergetic are:
- Pipelines
- Runs
- Recurring runs
- Experiments
¶ Pipelines
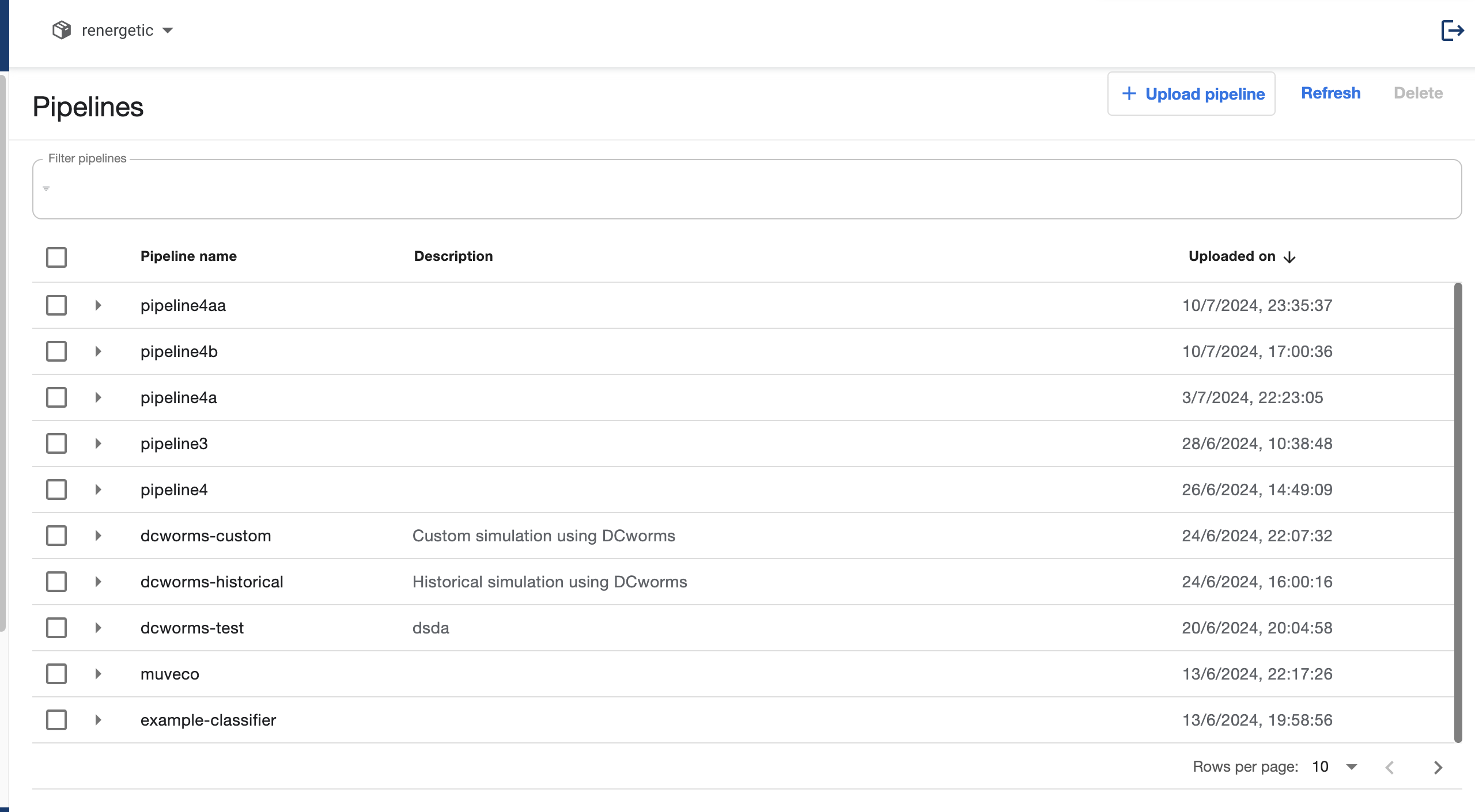
On this subpage new pipelines can be created or viewed. By clicking Upload Pipeline a new pipeline is deployed. It could be a new version of an existing pipeline or a new pipeline all together. There are two ways to create the pipeline by using an url to a GitHub Repository or to upload a file in .yaml format. All the pipelines in RENergetic have been created uploading a .yaml file. For more details view Pipeline Development in Python.
All pipelines are saved and can be used at any time. Therefore, name versioning is critical to make sure the correct pipeline is used.
In order to create new pipelines:
and then the following form pops up:
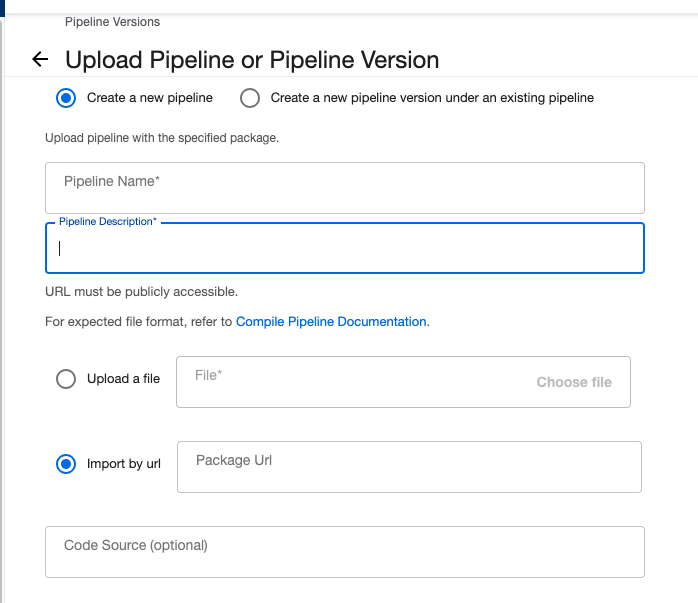
The yaml file will be added here.
¶ Runs
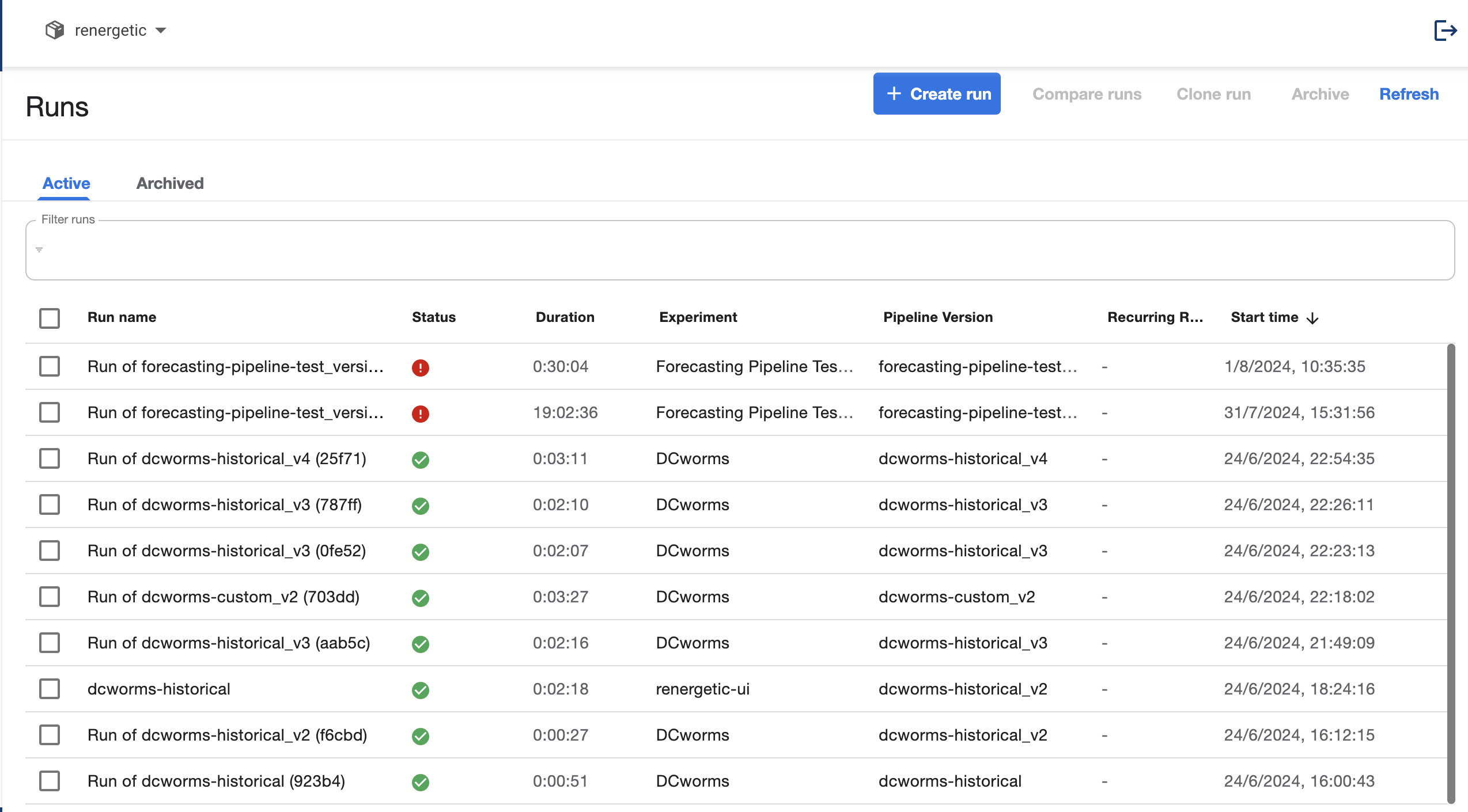
Here all the runs are shown, both the ones coming from individual execution, as well as the ones belonging to recurring runs. When creating a new run there is a need to link the pipeline to an experiment. Experiments are groupings of runs. It is required to run one pipeline and it is recommended to fully use it as it is very helpful to review past runs (See Experiments).
Here we show an example of how to run one execution of the forecasting-pipeline:
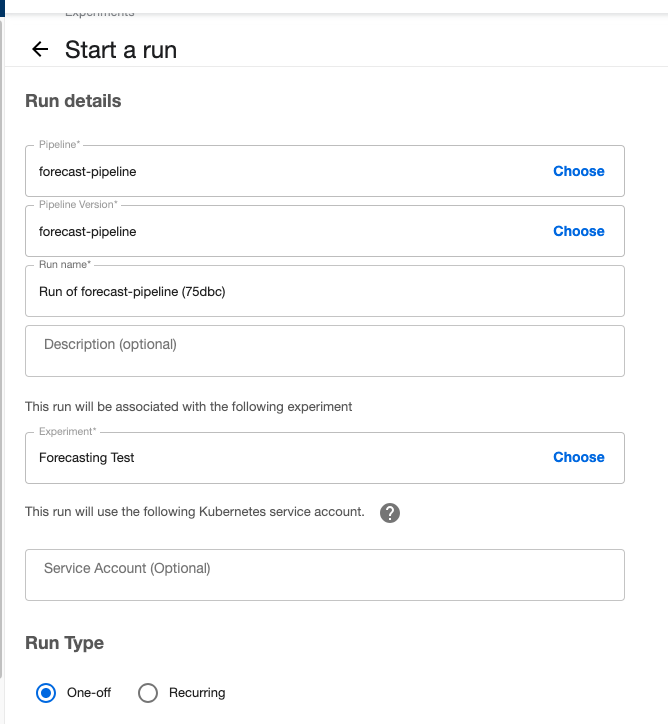
Furthermore, this run subpage can be used to do recurring runs, for which to set up the scheme in which the repetition happens (for instance, every day at 11:00).
In the recurring run section, all the created recurrring runs appear and can be activated, deactivated or eliminated. It also shows the result of the latest 5 runs from that recurring effort.
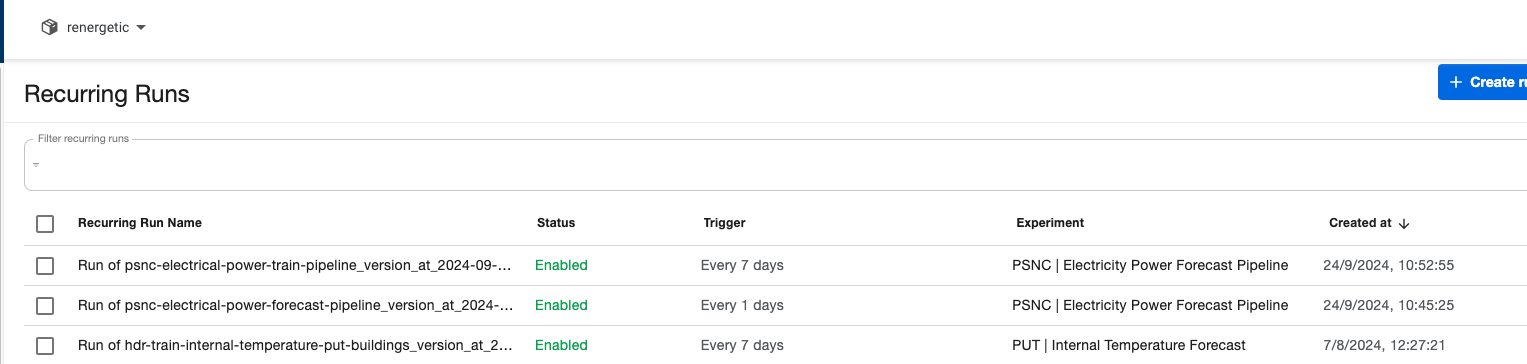
¶ Recurring Runs
In this page, it is possible to set and view the recurring runs. This happens in periodic intervals set up by the user. Only in this page, Recurring Runs can be terminated if necessary. However, in order to see individual executions of runs, it is necessary to go to the Runs subpage.
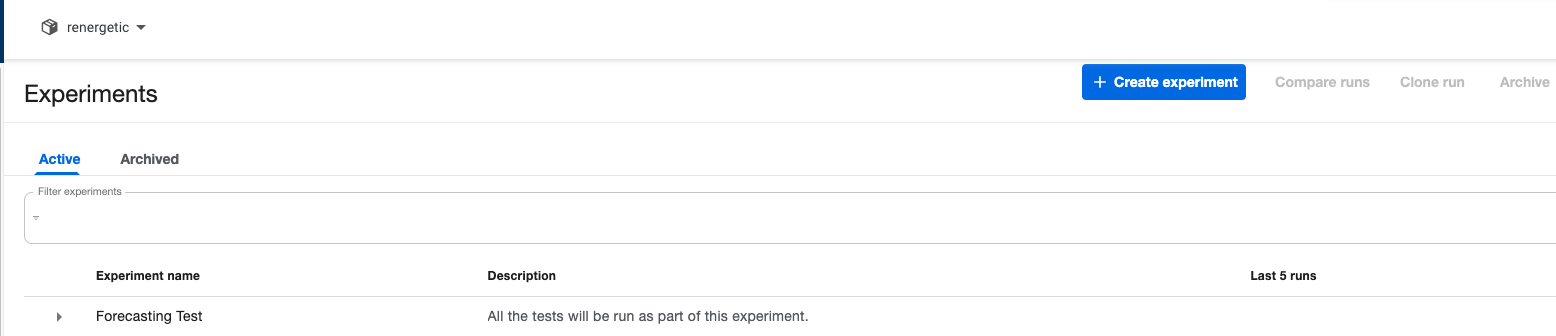
¶ Experiments
The Experiments page allows you to see detailed view of the individual runs for each of the groups of runs. It is not necessary to set up more than 1 experiment for KubeFlow to work. However is it convinient to have several, as it is easier to check the individual executions. Sometimes it is also recommended to create different experiments if training or forecasting should occur at different schedules. For instance, if the model will forecast for both each 2 days and each 6 hours, the executions of each 2 days will be harder to spot. This is just a matter of customization, as mentioned before it is not obligatory.